با استفاده از روشهای زیر میتوانید این صفحه را با دوستان خود به اشتراک بگذارید.
اندازه متن12
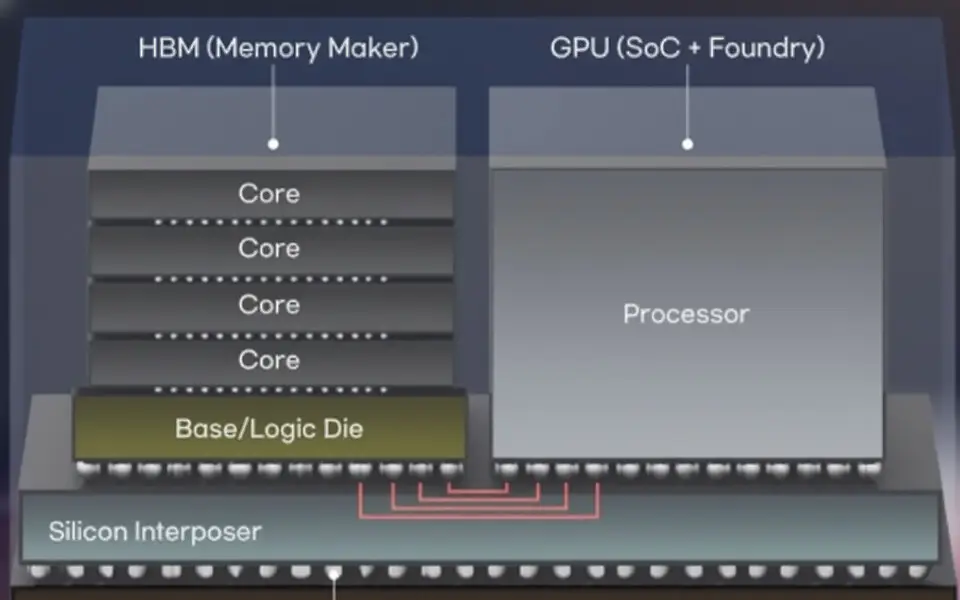
شرکتهای فناوری در حال بررسی یک تغییر بزرگ در طراحی HBM هستند و به دنبال تعبیه هستههای GPU به طور مستقیم در پشتههای حافظه نسل بعدی هستند. طبق گزارشهای صنعت کره، متا و NVIDIA در حال ارزیابی معماریهای HBM سفارشی هستند که هستههای GPU را در دای پایه دستگاههای HBM آینده ادغام میکنند. گفته میشود SK Hynix و Samsung در بحثهای اولیه مشارکت دارند.
HBM چندین دای DRAM را روی یک دای پایه که ورودی/خروجی خارجی را مدیریت میکند، قرار میدهد. انتظار میرود HBM4 سال آینده به تولید انبوه برسد و شامل یک کنترلر داخلی برای بهبود پهنای باند و کارایی باشد. ادغام هستههای GPU این مفهوم را چند قدم جلوتر میبرد، محاسبات را در خود حافظه توزیع میکند تا حرکت داده را کاهش دهد و مصرف انرژی را کم کند.
آیا HBM نسل بعدی، انقلابی در پردازش هوش مصنوعی است؟
منابع صنعتی میگویند این رویکرد میتواند با کاهش فاصله بین محاسبات و حافظه، عملکرد و بهرهوری انرژی را برای بارهای کاری هوش مصنوعی افزایش دهد. با این حال، این طراحی هنوز با چالشهای بزرگی مانند مساحت محدود دای در پشتههای مبتنی بر Through-Silicon Vias (TSV)، محدودیتهای تحویل توان و دشواری خنک کردن منطق GPU سنگین محاسباتی در داخل دای پایه روبرو است.
چالشها و فرصتهای ادغام GPU در HBM نسل بعدی
کیم جونگ هو، استاد دانشکده مهندسی برق در KAIST، گفت: «سرعت انتقال فناوری که در آن مرز بین حافظه و نیمهرساناهای سیستم برای پیشرفت هوش مصنوعی از بین میرود، شتاب خواهد گرفت.» و اضافه کرد: «شرکتهای داخلی باید اکوسیستم خود را فراتر از حافظه به بخش منطق گسترش دهند تا بازار HBM نسل بعدی را به دست بگیرند.»
در حال حاضر، رقابت در این عرصه بسیار داغ است و شرکتهای مختلف رویکردهای متفاوتی را دنبال میکنند. برای مثال، شتابدهنده Instinct MI430X که اخیراً توسط AMD رونمایی شده و بر اساس معماری AMD CDNA نسل بعدی ساخته شده است، از 432 گیگابایت حافظه HBM4 و پهنای باند حافظه 19.6 ترابایت بر ثانیه پشتیبانی میکند. از طرف دیگر، NVIDIA’s Vera Rubin Superchip رویکرد متفاوتی را اتخاذ میکند. هر GPU Rubin دو چیپلت محاسباتی در اندازه reticle را با هشت پشته HBM4 جفت میکند و حدود 288 گیگابایت HBM4 در هر GPU و تقریباً 576 گیگابایت HBM4 در سراسر Superchip کامل ارائه میدهد. با توجه به این تحولات، شرکتهایی که قابلیتهای بستهبندی و منطقی قوی دارند، سود خواهند برد، در حالی که فروشندگان صرف حافظه ممکن است برای حفظ رقابت، نیاز به گسترش به فناوریهای نیمهرسانای سطح سیستم داشته باشند.
همچنین، تحولات در حوزهی حافظه، به خصوص حافظههای DDR5، بسیار مهم هستند. شرکتها همواره در تلاشاند تا سرعت و ظرفیت این حافظهها را افزایش دهند. به عنوان مثال، میتوانید مقاله حافظه DDR5 چینی: جهش CXMT با DDR5-8000 را مطالعه کنید تا از آخرین پیشرفتها در این زمینه مطلع شوید.
آینده HBM نسل بعدی و GPU های تعبیه شده
ادغام GPU ها در HBM یک گام بزرگ به سوی محاسبات کارآمدتر و سریعتر است. این رویکرد نه تنها میتواند عملکرد را بهبود بخشد، بلکه مصرف انرژی را نیز کاهش میدهد، که برای کاربردهای هوش مصنوعی و یادگیری ماشین بسیار مهم است. با این حال، چالشهای فنی و اقتصادی زیادی وجود دارد که باید بر آنها غلبه کرد تا این فناوری به طور گسترده مورد استفاده قرار گیرد. با این حال، با توجه به رقابت شدید در این زمینه و تلاش شرکتهای بزرگ، میتوان انتظار داشت که شاهد پیشرفتهای چشمگیری در HBM نسل بعدی و GPU های تعبیه شده باشیم. همچنین، برای درک بهتر رقابت در عرصهی پردازندهها، میتوانید نگاهی به مقاله پردازشگر تانسوری گوگل: رقیب NVIDIA یا چالش Alphabet؟ بیاندازید.